RAG Architecture for Security - Lessons Learnt
RAG is the lynchpin for several AI application use cases -
- RAG helps reduce hallucination by giving context to the prompt
- RAG acts a short and long term memory for agents
- RAG and the vector db is the long term database for documentation
- RAG and the vector db acting as the 'front end' for mis typed user queries
We have been using RAG in several of the applications we are developing for all of the above use cases and here are some important, not so obvious lessons that we have learnt along the way
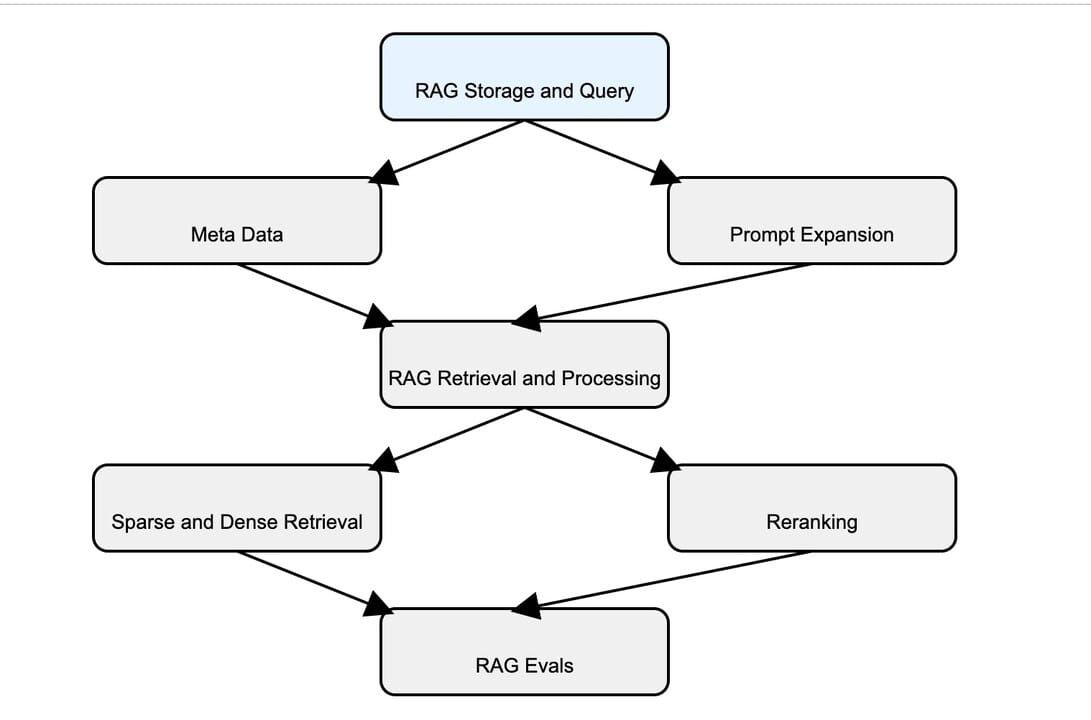
Lessons in RAG Storage and Query
Importance of Meta Data
When storing huge documents, it is important to organize them better so you know where to look , so the number of documents you are retrieving (topk) is less in number and are most relevant. While the commercial vector databases out there offer clusters, indices , having a description of the chunk of data is critical to hit the right chunk and using metadata of the chunk to save that information can be life saving. For compliance documents, we store the summary of the each of the compliance sections as metadata so we can reach into the right sections of the document.

Decoupling user query from RAG query (Prompt expansion)
When the users ask for 'give me all review periods in PCI DSS' , there are several types of reviews in the PCI dss docs and in corresponding vectors, so you want to pass multiple queries into the RAG with , 'log review', 'user access review' etc. Using prompt expansion will help your RAG queries independent of user queries.

RAG Retrieval and Processing
Sparse retrieval is as important as dense retrieval
Security is full of acronyms that a normal textual search than similarity can retrieve better results, so storing the data in both sparse and dense vectors is important. Encoding the docs with sparse encoding methods and maintaining those chunks, parallel querying both those sparse and dense indices will yield better results for the user

Reranking
After retrieval of the chunks, the re-ranking of chunks in relevancy to the original user question matters, the reranking helps a bunch in increasing the relevancy of the response before sending to LLM.

RAG query evals
There are several variables in each of the techniques above that needs to be tweaked . Maintaining ground truth test cases and evaluating the RAG responses against various user queries will help in continuously tweaking those variables.
Generative AI team at Transilience AI