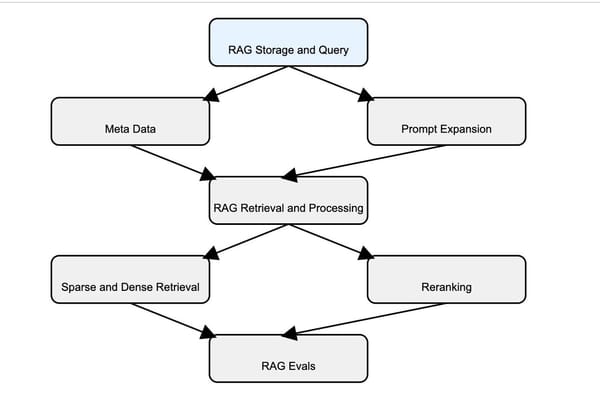
Is RAG Dead ?

First lets understand what the purpose of RAG is - its to provide right context to LLMs so LLMs can get you the "right answer", from the "right context" provided by you. If the context is not provided by you, the LLM will be free to pick whatever context its training weights light up during inference.
What RAG is not - Historically RAG is equated with vector databases and storing embeddings inside the vector databases.
If you want LLM to answer after considering the data and context provided by you, RAG is required.
There are a few historical reasons for "RAG is dead" sound byte
- LLM access to real time information: Historically LLMs did not have access to latest information, now they do.
- Long context support of LLMs
More recently, google Gemini released support for
Ability to mix prompts with inline pdfs (unlike OpenAI assistants where there is a different API). Here is an example of PCI DSS standard
from google import genai
from google.genai import types
import httpx
client = genai.Client()
doc_url = "https://www.commerce.uwo.ca/pdf/PCI-DSS-v4_0.pdf" # Replace with the actual URL of your PDF
# Retrieve and encode the PDF byte
doc_data = httpx.get(doc_url).content
prompt = "Summarize this document"
response = client.models.generate_content(
model="gemini-1.5-flash",
contents=[
types.Part.from_bytes(
data=doc_data,
mime_type='application/pdf',
),
prompt])
print(response.text)Gemini also supports direct calls of PDFs stored in gs (google storage) and ability to pass in multiple PDFs.
We at Transilience AI did a lot of testing and we migrated and simplified some of our architecture , here are our findings :
The need for chunking and embedding is over, especially for small documents
RAG has historically been equated to embeddings and chunking, and that part of RAG is for the most part dead (see below) because the foundational models are supporting inbuilt passing of PDFs and doing embeddings in the backend
Chunking is needed for only super large doc
Foundational models have limits on the size of the doc, 1000 pages and 50MB. If you have documents (or a combination of documents) which is larger than that you need chunking. The total length of the content should also fir into the context length, which is 2M tokens for Gemini
Cost of context tokens is high for large documents vs Chunks
With chunking and embedding each page of the document, you can hopefully pickup right chunks to give the LLM as opposed to the whole document. For large documents and pointed questions, if you are loading the whole doc then cost will be high
For a majority of our documents, we changed our pipeline to load the documents directly into LLM and not the chunks. We also realized that the part of RAG systems that have not gotten attention such as query transformation, query routing are more important now than before.
To summarize, below is the summary of pros and cons of each approach.
Direct PDF Integration Approach
Pros:
- Holistic Context Preservation:
- The entire PDF is uploaded and processed as a whole. This ensures that the document’s structure, layout, and internal relationships are maintained without disruption.
- Example: Using the Gemini 1.5 Flash File API, you can upload an entire PDF (up to 3,600 pages) so that the model sees a continuous context.
- Reduced Need for Manual Pre-Processing:
- No need to segment the document into multiple chunks. This minimizes the risk of context fragmentation, where critical information might be split across chunks.
- Simplifies workflow—upload the document once, then use a prompt (e.g., "Summarize this document") to generate the output.
- Direct Use of Document Metadata:
- Since the document is integrated directly, any inherent metadata (such as layout or formatting cues) remains available, potentially enhancing understanding.
Cons:
- Token and Processing Constraints:
- Even though long-context LLMs now support more tokens, processing an entire large PDF may still push token limits and require high computational resources.
- May lead to higher latency if the document is very large.
- Cost Considerations:
- Direct integration might incur higher cost when processing entire documents—especially if only a portion of the data is actually relevant to the query.
- Potential for Noise:
- If the PDF contains a mix of useful and irrelevant information, the model must process all of it, which could dilute focus unless carefully managed via prompt design.
Chunking Approach
Pros:
- Focused Retrieval:
- By splitting the document into smaller, manageable chunks (pages or sections), only the most relevant pieces are retrieved and used in the prompt. This helps filter out noise.
- It can significantly reduce the token count per query, leading to cost efficiency and faster processing.
- Flexibility in Data Selection:
- Allows for dynamic routing where only chunks that contain the answer or context are selected. This is particularly useful when a document is long and only specific sections are needed.
- Enhanced Relevance Filtering:
- Combining chunking with robust retrieval algorithms (such as vector-based similarity search) helps ensure that only the most pertinent parts of a document are fed to the model.
Cons:
- Risk of Context Fragmentation:
- Breaking a document into chunks can lead to loss of holistic context if the segmentation is not aligned with natural document boundaries.
- Important relationships or cross-chunk information may be missed if the retrieval or merging strategy isn’t optimal.
- Additional Pre-Processing Overhead:
- Requires an extra step to segment the PDF into meaningful chunks, which might need manual tuning or sophisticated algorithms to avoid splitting in the middle of important sections.
- Routing Complexity:
- The system must accurately determine which chunk or set of chunks contains the needed context. Inaccurate routing can result in incomplete or misleading responses.